Build knowledge graphs your AI can reason over
The only graph database with first-class n-ary relations and a strict type-system
- 1
- 2
- 3
- 4
- 5
- 6
- 7
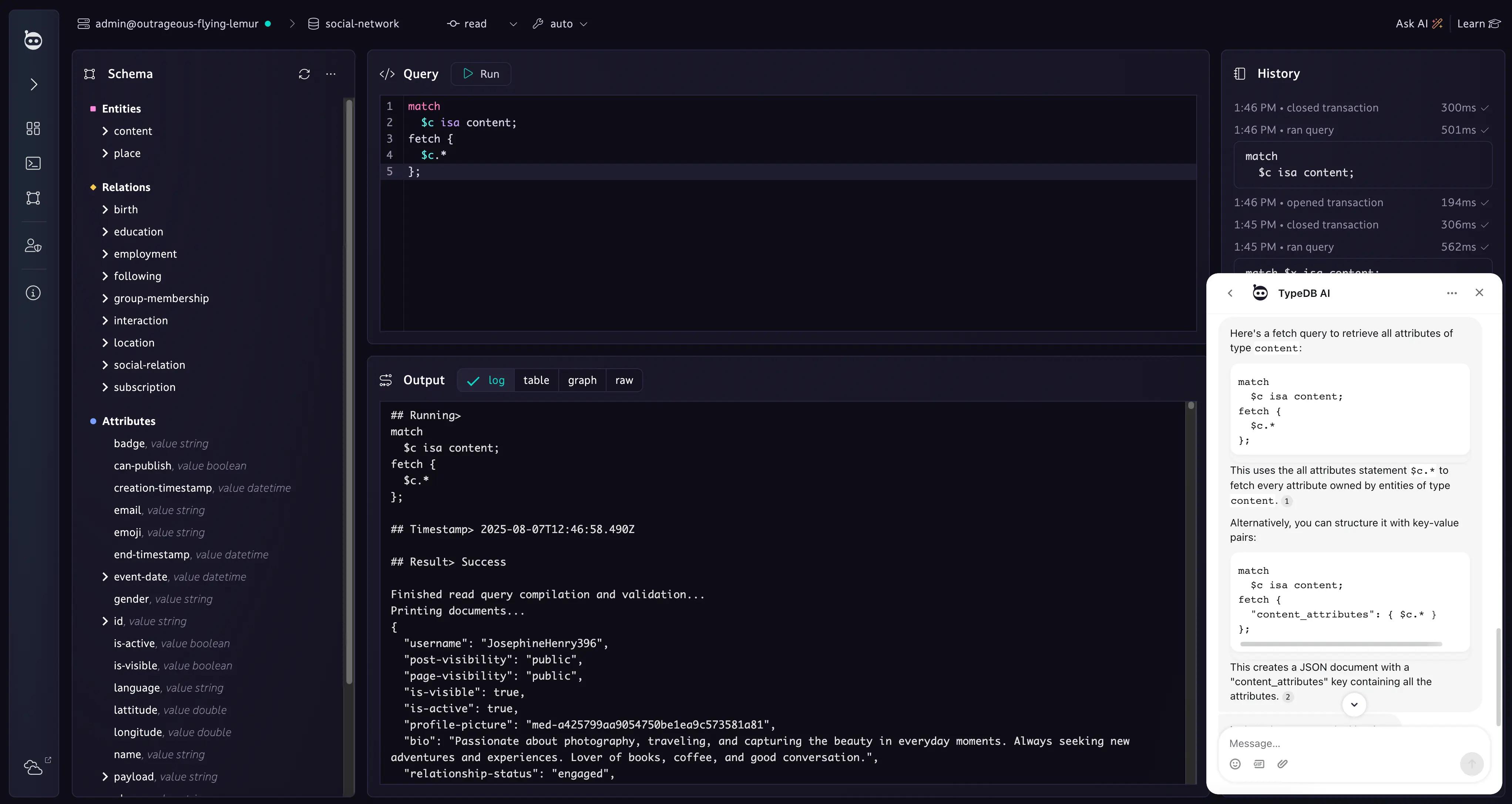
insert
$cypher isa language;
$typeql isa language;
$evo isa evolution (past: $cypher, future: $typeql);
Learn about the hot topics at TypeDB





Structured for machines, intuitive for humans
TypeQL is a declarative query language built on modern programming paradigms. Its structured, human-readable syntax means agents parse it efficiently, which results in more efficient token usage by agents.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
define
attribute username, value string;
attribute page-visibility, value string @values("public", "private");
attribute address, value string;
attribute dob, value date;
entity profile @abstract,
owns username @key,
owns page-visibility @card(1);
entity person,
sub profile,
owns dob,
plays employment:employee;
entity company,
sub profile,
owns address @card(0..),
plays employment:employer;
relation employment,
relates employer,
relates employee;Better suited for complexity
Our type system and n-ary relations let you describe your domain at a high level, then refine as complexity grows. Clean iteration and inheritance means you can model highly complex systems accurately and efficiently.
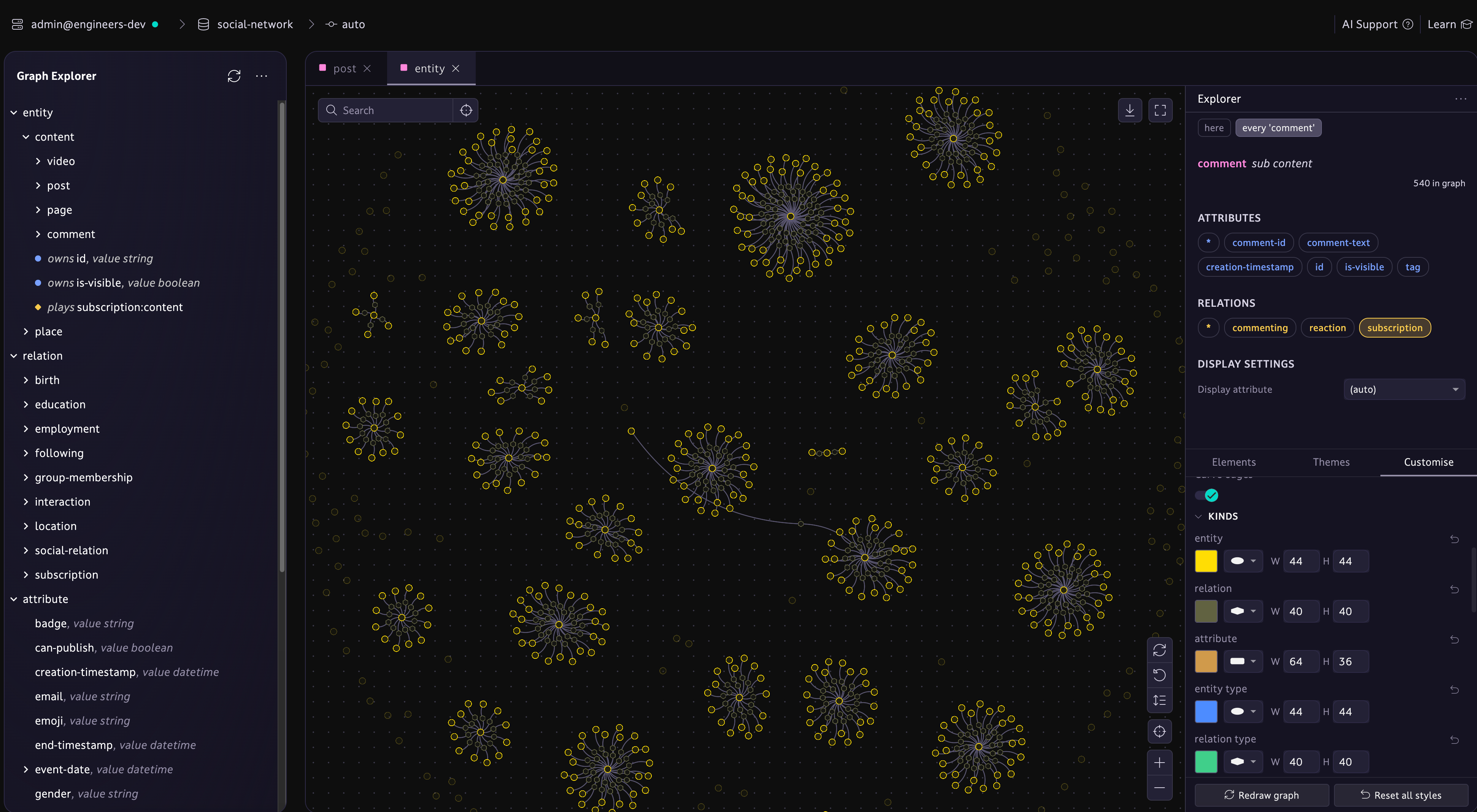
A programming language, not just a schema
With TypeQL, you describe your data like code. It’s readable, writable, and logical, enabling full expressiveness with real constraints and inference.
TypeDB
Find users that have access to different types of resources. Return user emails, resource IDs and resource types
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
match
$user isa user;
$resource isa! $resource-type;
$resource-type sub resource;
resource-ownership (resource: $resource, owner: $user);
fetch {
"email": $user.email,
"resource-id": $resource.id,
"resource-type": $resource-type
};Graph
In graph DBs, properties are attached directly to the nodes that own them, rather than being nodes themselves
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
MATCH
(user:User)-[:OWNS]->(rsrc:Resource)
WITH
rsrc,
[user.primary_email] + user.alias_emails AS emails,
labels(rsrc) AS resource_types,
keys(rsrc) AS properties
UNWIND emails AS email
UNWIND resource_types AS resource_type
WITH
rsrc, email, resource_type, properties,
{
File: "path",
Directory: "path",
Commit: "hash",
Repository: "name",
Table: "name",
Database: "name"
} AS id_type_map
WHERE resource_type IN keys(id_type_map)
AND id_type_map[resource_type] IN properties
RETURN email, resource_type, rsrc[id_type_map[resource_type]] AS id
Relational
In relational DBs, define one table for each resource type, using a UNION ALL query and JOINs to fetch interconnected data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
SELECT
ue.email AS email,
'file' AS resource_type,
f.path AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN files f
ON r.id = f.resource_id
UNION ALL
SELECT
ue.email AS email,
'directory' AS resource_type,
d.path AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN directories d
ON r.id = d.resource_id
UNION ALL
SELECT
ue.email AS email,
'commit' AS resource_type,
c.hash AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN commits c
ON r.id = c.resource_id
UNION ALL
SELECT
ue.email AS email,
'repository' AS resource_type,
re.name AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN repositories re
ON r.id = re.resource_id
UNION ALL
SELECT
ue.email AS email,
'table' AS resource_type,
t.name AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN tables t
ON r.id = t.resource_id
UNION ALL
SELECT
ue.email AS email,
'database' AS resource_type,
f.name AS id
FROM users u
JOIN user_emails ue
ON u.id = ue.user_id
JOIN resource_ownerships ro
ON u.id = ro.user_id
JOIN resources r
ON ro.resource_id = r.id
JOIN databases d
ON r.id = d.resource_id;
Document
In document DBs, freeform structures make writes trivial, but reading and validating data becomes a significant challenge
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
db.resource_ownerships.aggregate( [
{
$lookup:
{
from: "resources",
localField: "resource",
foreignField: "_id",
as: "resource"
}
},
{
$unwind:
{
path: "$resource"
}
},
{
$lookup:
{
from: "users",
localField: "owner",
foreignField: "_id",
as: "owner"
}
},
{
$unwind:
{
path: "$owner"
}
},
{
$unwind:
{
path: "$owner.emails"
}
},
{
$addFields:
{
resource_id: {
$switch: {
branches: [
{
case: {
$eq: ["$resource.resource_type", "file"]
},
then: "$resource.path"
},
{
case: {
$eq: ["$resource.resource_type", "directory"]
},
then: "$resource.path"
},
{
case: {
$eq: ["$resource.resource_type", "commit"]
},
then: "$resource.hash"
},
{
case: {
$eq: ["$resource.resource_type", "repository"]
},
then: "$resource.name"
},
{
case: {
$eq: ["$resource.resource_type", "table"]
},
then: "$resource.name"
},
{
case: {
$eq: ["$resource.resource_type", "database"]
},
then: "$resource.name"
}
]
}
}
}
},
{
$project: {
_id: false,
email: "$owner.emails",
resource_type: "$resource.resource_type",
id: "$resource_id"
}
}
] )
Ideal for agentic infrastructure
Graphs force agents to construct their own context through massive traversals. TypeDB gives agents structured, typed knowledge they can reason over. The result is agents that have a deeper understanding, and are more token efficient
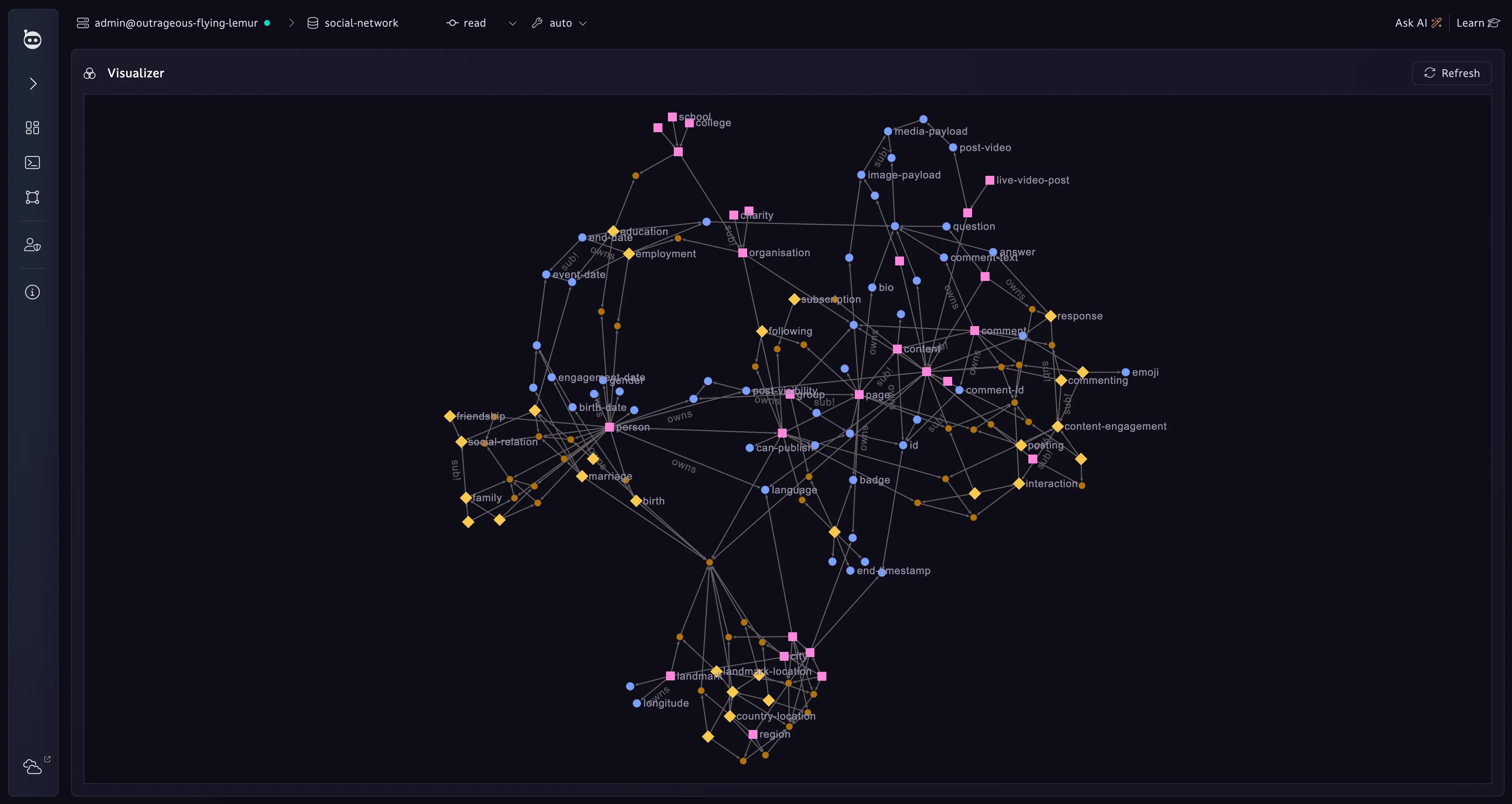
Explore with our proprietary web studio
Want to dive in and see what TypeDB can do? Sign up to Cloud and connect instantly to our web studio to see what you can do in just a few minutes.
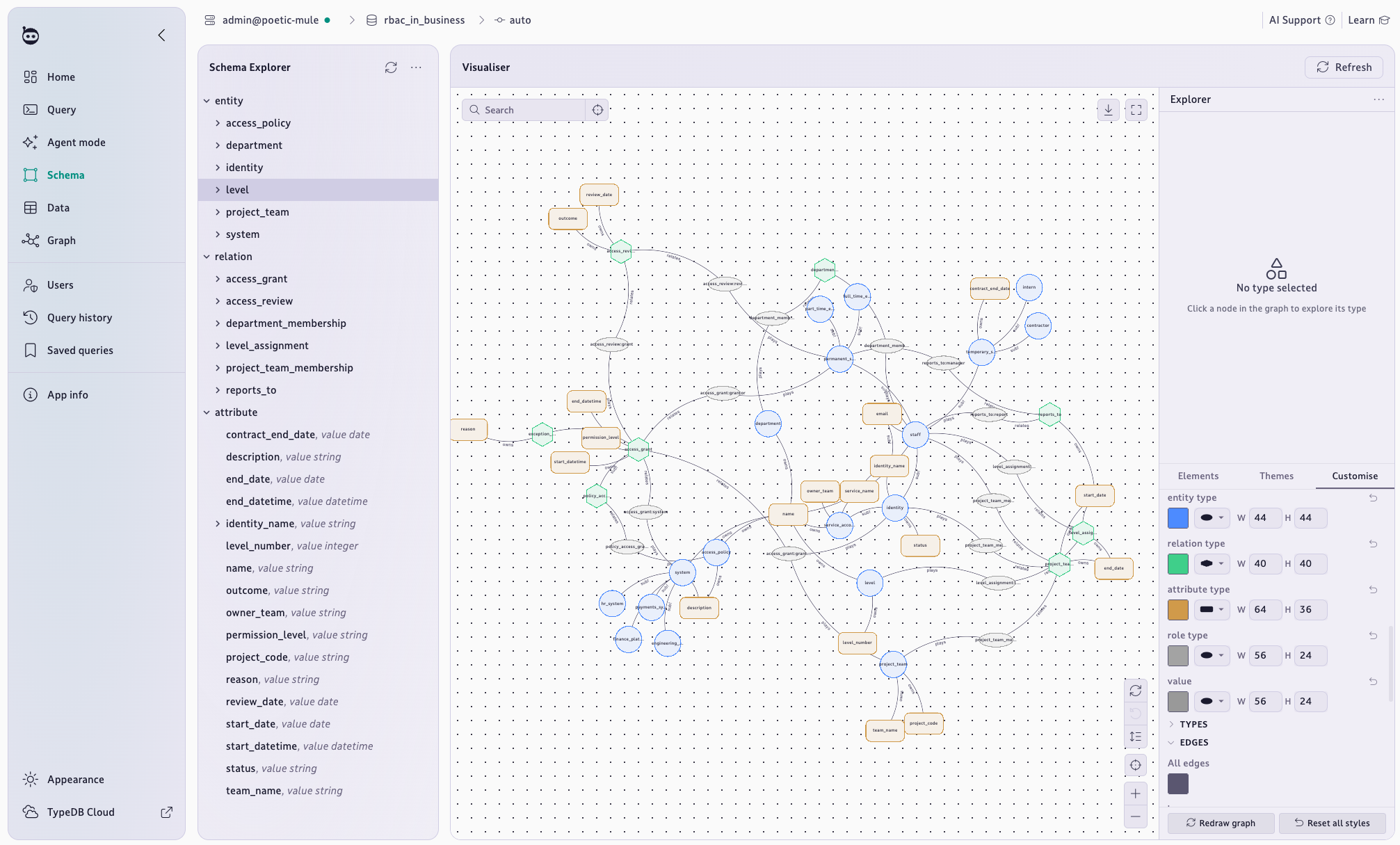
Collaborate with other builders
We are used by major enterprises, cutting edge AI businesses, world-leading researchers, and everything else you can imagine.
GitHub
Discord
YouTube
Leverage the power of programming.
In your database
Using the Polymorphic-Entity-Relations-Attribute (PERA) model as the basis of TypeQL leads to a general, expressive, intuitive, and strongly typed language! Since data must be instantiated from the schema, the system can make strong guarantees about data integrity and shape.
Write less to do more
Queries are shorter, more intuitive, and more expressive. You don’t have to specify how data joins; Just say what you need and retrieve it in a simple, single database call.
Eliminate a significant amount of your tech debt
Data logic belongs in the structure, not the query. Our query variables match all valid types so doesn’t need updating even when you add new subtypes.
Your data holds more answers than you know
TypeDB is the only database built for interconnected data and intelligent applications. Build systems that understand, reason, and adapt, solving problems traditional databases cannot.
Batteries included
Connect your production application with our dedicated drivers, supporting the major languages, with more added regularly.




Useful resources to get started




Start free, upgrade when ready
Go to production in weeks, not months
TypeDB delivers a clear, structured data model and a human-readable, beautiful query language, ideal for powering agentic systems, cyber threat intelligence, robotics and much more.