VibeRec Post-Mortem

Dmitrii Ubskii
This project was a created as a part of the TypeDB x Claude hackathon. Follow the link to learn more about the hackathon and see other projects we made!
For the hackathon I decided I’d need something that could leverage a relatively large database, and pull out some insights from the data. In preparation, I browsed kaggle datasets looking for something that was less of a downer than medical or financial data. I eventually found a dataset of movie ratings called MovieLens1.
By the time the hackathon clock started, the idea has crystallized: an interactive recommender, à la Steam.

Steam builds a user profile based on the games they play and the time they play them for, then provides them two knobs to twist: how popular a game is overall vs with the user’s specific niche, and how recently it was released, which is just a threshold. I figured I could do something like that for movies instead.
The Recommendation Engine
A simple way to model preferences is to assign each user and each movie a -dimensional vector such that the dot product of those two vectors produces the rating the user gave to the movie. If we gather all the data into a matrix , this translates to finding two matrices, a matrix of user vectors and a matrix of movie vectors such that . Here, is the number of users in our dataset, and is the number of movies.
A common way to factorize a matrix like that is the singular value decomposition (SVD), which would split it into three matrices, , , and , such that . and are just as described before, with an additional constraint that each row vector in the matrix is unit, i.e. has length 1. The extra term is there to scale the values to get us out of the [-1, 1] range.
The issue is, SVD requires a complete matrix. Not every user has rated every movie, so we have a lot of missing values. If we try to fill in the blanks with some default values, the SVD model will simply reproduce tham instead of attempting to predict the actual rating the user would have given to the movie, and that’s no good.
Fortunately, this has been a problem for online recommendation systems for a long time. I quickly settled on the variant of SVD called “probabilistic matrix factorization” (PMF) 2. It was created, as far as I can tell, for the Netflix Prize competition, and is simple enough to grasp and use.
The canonical version of PMF is , where:
- is the estimated rating of movie by user ,
- is the overall bias of the dataset,
- and are the corresponding biases: how good movie is / how generous user is with their ratings,
- is the movie vector,
- and is the user embedding.
If we forcibly set all biases to zero, we get the much simpler unbiased version which is just , exactly the form we were looking for. It is less accurate than the biased version, where the biases capture rating tendencies of users as a whole, but the simplicity of the model was too attractive to pass up.
The algorithm was implemented by the Surprise scikit for SciPy3. Surprise also has the MovieLens 1M dataset built in, but I discovered that after I had run a bunch of experiments on my own with MovieLens 32M, and I didn’t feel like downgrading to 1M.
For this project I’ve set the embedding vector size to 20, and disabled the bias term to keep things simple. This resulted in RMSE of around 0.82, that is to say the estimate is, on average, within 0.82 stars of the true rating.
Once the user has rated 10 movies, we can estimate their embedding vector by putting the embeddings of the movies they’ve rated into a matrix and the ratings into the vector , and solving the equation for the user vector by least-squares.
You may be asking, “with only 10 data points, wouldn’t the user’s embedding overfit terribly?” The answer is yes. Yes it would.4
The Rating Page

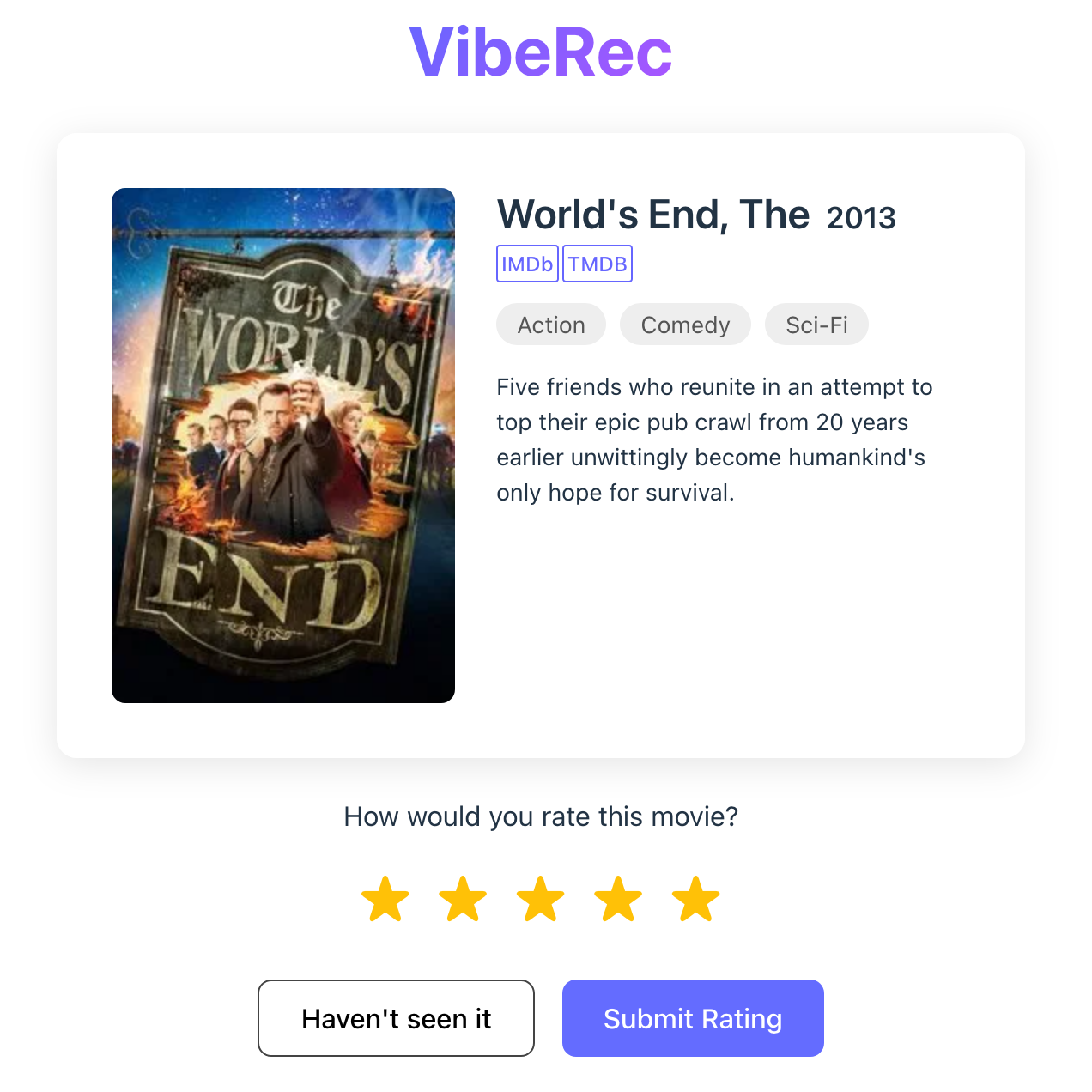
The rating page is a simple React app that presents the user with a random movie and asks them to rate it. TypeDB doesn’t have a way to fetch a random movie, so I just fetch all the movies and pick one at random on the backend. It asks TMDB for the movie’s poster, title, and description, and provides links to the movie’s page on IMDb and TMDB (helpfully supplied by the MovieLens dataset). Once the user has rated 10 movies, the backend computes the user’s embedding vector and tells the frontend that it’s ready to recommend movies.
The Recommendations Page

Since TypeDB does not (yet?) have any built-in vector handling or user-defined non-TypeQL functions, the only way to determine the estimated user scores for movies is to do it in the backend. I’ve already had to fetch all the data for the ratings page, so that’s not a huge deal. It does mean that TypeDB is not really being used for anything other than data storage and embedding cache. For a demo, that’s fine.
The recommendation page features three sliders to adjust the recommendations. The time slider controls a simple filter by release year,
while the popularity and genre sliders control how much weight is given to the estimated user’s score, the user’s genre preferences, and the average rating of the movie.
The genre score is computed by taking the genres of all the movies the user has rated, and estimating the user’s “genre rating” for each genre as the average of the ratings they gave to movies in that genre.
Where Claude?
You might be wondering why there’s no mention of Claude in this Claude-themed hackathon post-mortem.
On day one, I let it chug away working on the frontend mockup while I myself was experimenting with the dataset in Jupyter and researching recommender systems. I checked in occasionally to see what it has done and steered it when needed, but otherwise left it mostly on its own.
On day two I actually dug into the generated code and went to work on clean up. Claude seems very eager to duplicate code it could reuse. There were three ways to represent a movie’s data in different components, and even though the rendered webpage looked alright, the CSS was a lot less coherent than it could have been. Most of it I fixed using Claude, too, though the final cleanup of little weirdnesses scattered throughout I did by hand.
I’m not sure I could have finished the frontend without Claude in time for the deadline, given my experience with React measures in hours (up to around twelve with this project!). I could probably have taken an existing template and adapted it for my needs, but I think in that case I would have learned even less about React than I did reviewing the generated code and making sure it all made sense.
My general impression is mixed. I don’t know how much time it saved me, if any at all. It saved me from having to write TypeScript up until the point I had to anyway. It generated TODO comments instead of implementing functionality until I pointed them out.
The bottom line is, as far as I’m concerned, every line of code I commit is mine. And if it’s generated by an LLM, I must to have confidence in it before it ever hits git.
Conclusion
Overall, this was a fun way to scratch the surface of recommender systems, as well as see how easy TypeDB is to use in a project like this. I am fairly pleased with the way it’s turned out.
You can find the source code on my GitHub.
Footnotes
- https://grouplens.org/datasets/movielens/ ↩︎
- Ruslan Salakhutdinov and Andriy Mnih. Probabilistic matrix factorization. 2008. URL: https://papers.nips.cc/paper/3208-probabilistic-matrix-factorization.pdf ↩︎
- https://surprise.readthedocs.io/en/stable/matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.SVD ↩︎
- For completeness, I tried reducing the dimension to 5, which did not perform that much worse in training with RMSE of around 0.85, but it didn’t (subjectively) feel any worse or better when it came to recommendations. I also tried requiring more ratings from the user, but it was way too tedious to find movies I could actually rate without any sort of search function, so I quickly abandoned that route. Committing to the based PMF from the start would have probably been the better strategy. ↩︎