Crash course - graph database users
This crash course pathway is designed to give a concise overview of the main aspects of working with TypeDB and TypeQL for users coming from graph databases. If you do not have experience with graph databases, you can check out our other pathways instead. Graph query examples in this crash course use Neo4j syntax.
|
If you would like to follow along with the examples in this crash course, make sure you have completed the environment setup. |
Coming from graph databases
As a modern database built on highly expressive and type-safe foundations, TypeDB is designed to elegantly model data structures that are tricky to express in graph databases, including:
-
Non-binary edges.
-
Undirected edges.
-
Edges between edges.
-
Label hierarchies.
TypeDB is able to express them using high-level declarative syntax, in addition to enforcing the integrity of the data using an advanced constraint language.
Key similarities and differences
TypeDB shares several common traits with graph databases:
-
Data is structured using vertices and edges.
-
Both vertices and edges have labels and properties.
-
Edges are stored as references to their endpoint vertices for efficient traversal.
-
The database enforces edge integrity and ACID guarantees.
It also has several differences:
-
Edges are implemented as hyperedges, and can link any number of vertices.
-
Edges can also be nested, allowing them to link other edges too.
-
Edge endpoints are defined with specific labels, rather than by edge direction.
-
Properties are stored as independent vertices, connected to their parent vertices/edges.
-
Permitted data structures must be pre-defined in the schema before data can be inserted.
Terminology comparison
TypeDB uses distinct terminology to graph databases. The following table gives a comparison of the key terms used to describe data in graph databases, and their equivalents in TypeQL.
| Graph term | TypeDB term |
|---|---|
Vertex |
Entity |
Edge |
Relation |
Property value |
Attribute |
The next table compares the key terms used to describe how these data structures are classified.
| Graph term | TypeDB term |
|---|---|
Vertex label |
Entity type |
Edge label |
Relation type |
Property key |
Attribute type |
|
While these comparisons are equivalent as far as database theory is concerned, they may not always apply well in practice. When converting graph models to TypeDB, these comparisons should be taken as guidelines rather than rules. |
Using entity types
Before we can begin inserting entities, we must first define the necessary entity types and their attribute types. This is different to in schemaless graph databases, where vertices can be inserted without having to define their labels in advance. To define new types, we use a Define query. The following query defines a new entity type publisher along with an attribute type name for it. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
publisher sub entity,
owns name;
name sub attribute, value string;The above query contains the following TypeQL keywords:
-
define: Used to indicate the beginning of a Define query. -
sub: Used to define a new entity, relation, or attribute type. -
entity: The root type from which all entity types are subtyped. -
owns: Used to define an entity or relation type to be the owner of an attribute type. -
attribute: The root type from which all attribute types are subtyped. -
value: Used to define the value type of an attribute type. Attribute types must have a value type declared.
Inserting entities
With this entity type defined, we can now begin inserting corresponding data. To insert data, we use an Insert query. The following query inserts four new publishers into the database. Using a data session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
insert
$publisher-1 isa publisher, has name "Springer";
$publisher-2 isa publisher, has name "Thames & Hudson";
$publisher-3 isa publisher, has name "Andrews McMeel Publishing";
$publisher-4 isa publisher, has name "W.W. Norton & Company";This is equivalent to the following Cypher query.
CREATE
(publisher1:Publisher { name: "Springer" }),
(publisher2:Publisher { name: "Thames & Hudson" }),
(publisher3:Publisher { name: "Andrews McMeel Publishing" }),
(publisher4:Publisher { name: "W.W. Norton & Company" })This query introduces three new TypeQL keywords:
-
insert: Used to indicate the beginning of theinsertclause in an Insert query or Update query. -
isa: Used to declare the type of an entity or relation. -
has: Used to declare an attribute of an entity or relation.
The query contains four variables, indicated by the mandatory $ prefix. Each variable represents an entity to be inserted. The isa statements then specify the types of these entities, and the has statements specify the types and values of their attributes.
Reading entities
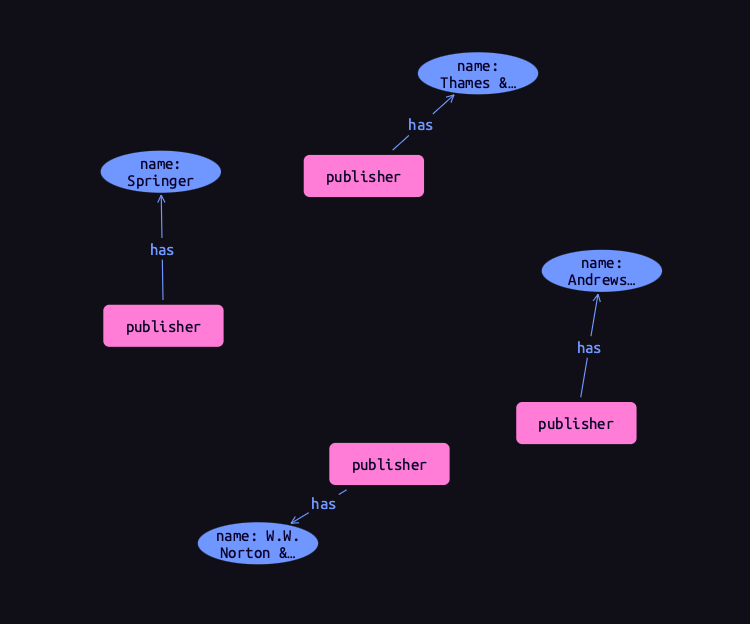
Let’s now read the data we inserted. To begin with, we’ll retrieve the publishers and their names we inserted with the following Get query. Using a data session and read transaction, ![]() run this query.
run this query.
match
$publisher isa publisher, has name $name;
get $publisher, $name;When run in TypeDB Studio, the results of Get queries are displayed by the graph visualizer. You should see the following result.
|
If a graph visualization is not displayed for the results of a Get query in TypeDB Studio, ensure the |
This is equivalent to the following Cypher query.
MATCH
(publisher:Publisher)
RETURN
publisher, publisher.nameThis query introduces two new TypeQL keywords:
-
match: Used to indicate the beginning of thematchclause in a Get query, Fetch query, Insert query, Delete query, or Update query. -
get: Indicates the beginning of thegetclause in a Get query, which describes which vertices should be returned in the graph visualization.
TypeDB Studio shows entities as pink rectangles and attributes as blue ovals in graphs. Entities are connected to their attributes by arrows labeled with the has keyword. We can see that four results have been returned, corresponding to the previously inserted data. The graph shows one vertex per variable in the get clause per result. Unlike in graph databases, attributes are vertices independent of the entities that own them, so we need to match and get them in addition to their owners, or they will not appear in the graph.
Defining entity type hierarchies
The entity type publisher that we defined previously was declared to be a subtype of the root type entity by using the sub keyword. However, we can also declare types to be subtypes of existing types. In the following query, we define four new entity types in a type hierarchy, along with some new attribute types. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
book sub entity,
abstract,
owns isbn-13 @key,
owns isbn-10 @unique,
owns title,
owns genre,
owns page-count,
owns price;
paperback sub book,
owns stock;
hardback sub book,
owns stock;
ebook sub book;
contributor sub entity,
owns name;
isbn sub attribute, abstract, value string;
isbn-13 sub isbn;
isbn-10 sub isbn;
title sub attribute, value string;
genre sub attribute, value string;
page-count sub attribute, value long;
price sub attribute, value double;
stock sub attribute, value long;Here we have introduced three new TypeQL keywords:
-
abstract: Used to define an entity, relation, or attribute type to be abstract. -
@key: Used in anownsstatement to specify a key attribute of an entity or relation type. -
@unique: Used in anownsstatement to specify a unique attribute of an entity or relation type.
This query defines a new type hierarchy of book types, described by an abstract type book with three subtypes: paperback, hardback, and ebook. The attribute type ownerships of book are automatically inherited by its subtypes. Meanwhile, ownership of stock is defined individually at the subtype level. This gives complete control over which data instances are permitted to own which attributes.
Inserting entities into type hierarchies
When inserting data into a type hierarchy, we declare only the exact type of the data instances. For instance, when we insert an entity of type paperback, we do not have to also declare that it is of type book, as the schema contains the context necessary for the database to infer this. In the following query we insert five books of different types. Using a data session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
insert
$book-1 isa paperback,
has isbn-13 "9781489962287",
has title "Interpretation of Electron Diffraction Patterns",
has page-count 199,
has price 47.17,
has genre "nonfiction",
has genre "technology",
has isbn-10 "148996228X",
has stock 15;
$book-2 isa paperback,
has isbn-13 "9780500026557",
has title "Hokusai's Fuji",
has page-count 416,
has price 24.47,
has genre "nonfiction",
has genre "art",
has isbn-10 "0500026556",
has stock 11;
$book-3 isa paperback,
has isbn-13 "9780500291221",
has title "Great Discoveries in Medicine",
has page-count 352,
has price 12.05,
has genre "nonfiction",
has genre "history",
has isbn-10 "0500291225",
has stock 18;
$book-4 isa hardback,
has isbn-13 "9780740748479",
has title "The Complete Calvin and Hobbes",
has page-count 1451,
has price 128.71,
has genre "fiction",
has genre "comics",
has isbn-10 "0740748475",
has stock 6;
$book-5 isa ebook,
has isbn-13 "9780393634563",
has title "The Odyssey",
has page-count 656,
has price 13.99,
has genre "fiction",
has genre "classics",
has isbn-10 "0393634566";We could emulate the type hierarchy in a graph database by giving the vertices multiple labels, as we do in the Cypher query below.
CREATE
(book1:Paperback:Book {
isbn13: "9781489962287",
title: "Interpretation of Electron Diffraction Patterns",
pageCount: 199,
price: 47.17,
genres: ["nonfiction", "technology"],
isbn10: "148996228X",
stock: 15
}),
(book2:Paperback:Book {
isbn13: "9780500026557",
title: "Hokusai's Fuji",
pageCount: 416,
price: 24.47,
genres: ["nonfiction", "art"],
isbn10: "0500026556",
stock: 11
}),
(book3:Paperback:Book {
isbn13: "9780500291221",
title: "Great Discoveries in Medicine",
pageCount: 352,
price: 12.05,
genres: ["nonfiction", "history"],
isbn10: "0500291225",
stock: 18
}),
(book4:Hardback:Book {
isbn13: "9780740748479",
title: "The Complete Calvin and Hobbes",
pageCount: 1451,
price: 128.71,
genres: ["fiction", "comics"],
isbn10: "0740748475",
stock: 6
}),
(book5:Ebook:Book {
isbn13: "9780393634563",
title: "The Odyssey",
pageCount: 656,
price: 13.99,
genres: ["fiction", "classics"],
isbn10: "0393634566"
})However, this is not quite the same. The graph database does not have the context to infer that the Paperback, Hardback, and Ebook labels represent subtypes of the Book label, which can lead to problems with data integrity and declarative querying.
Reading entities from type hierarchies
When reading data from type hierarchies, we can match that data using any of its types. In the following query, we retrieve all the attributes of all books. When we match the books, we do not specify which type of book we are looking for, by matching against the supertype book. This matches instances of paperback, hardback, and ebook. Using a data session and read transaction, ![]() run this query.
run this query.
match
$book isa book, has title $title;
get $book, $title;Results
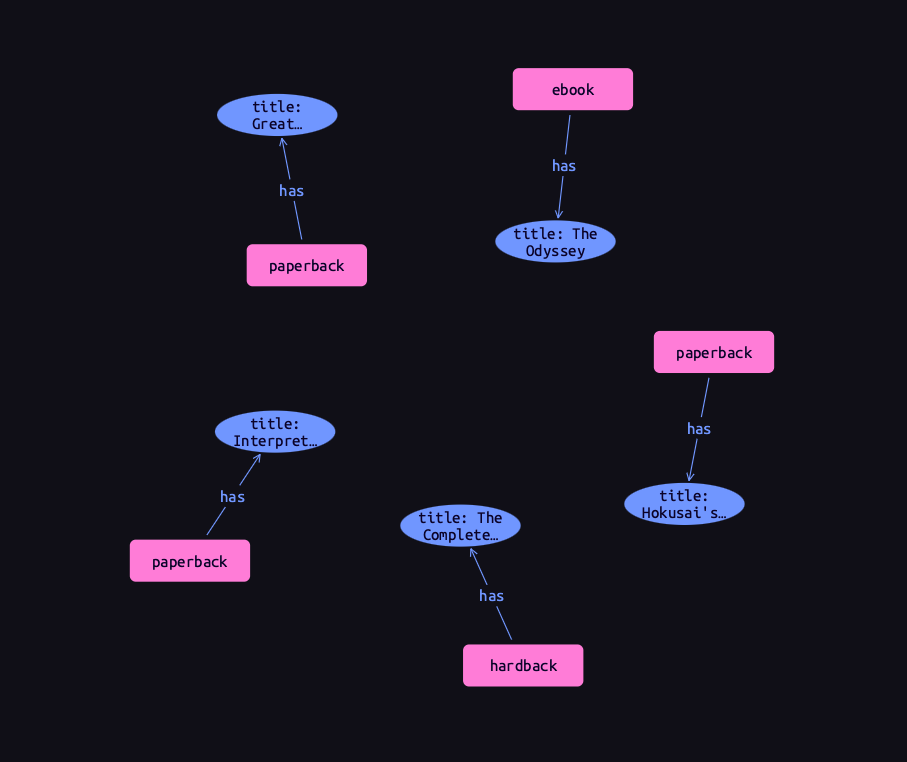
This is equivalent to the following Cypher query.
MATCH
(book:Book)
RETURN
book, book.titleSimilarly, we could specify the type of $book to be paperback instead of book, for instance, and then only entities of that type and their titles would be retrieved.
Working with globally unique attributes
We have seen that attributes are stored as vertices separate to their owners, and this comes with a powerful advantage over traditional graph databases that implement the labeled property graph model. To see this, we will run the following query. Using a data session and read transaction, ![]() run this query.
run this query.
match
$book isa book,
has title $title,
has genre $genre;
get $book, $title, $genre;Results
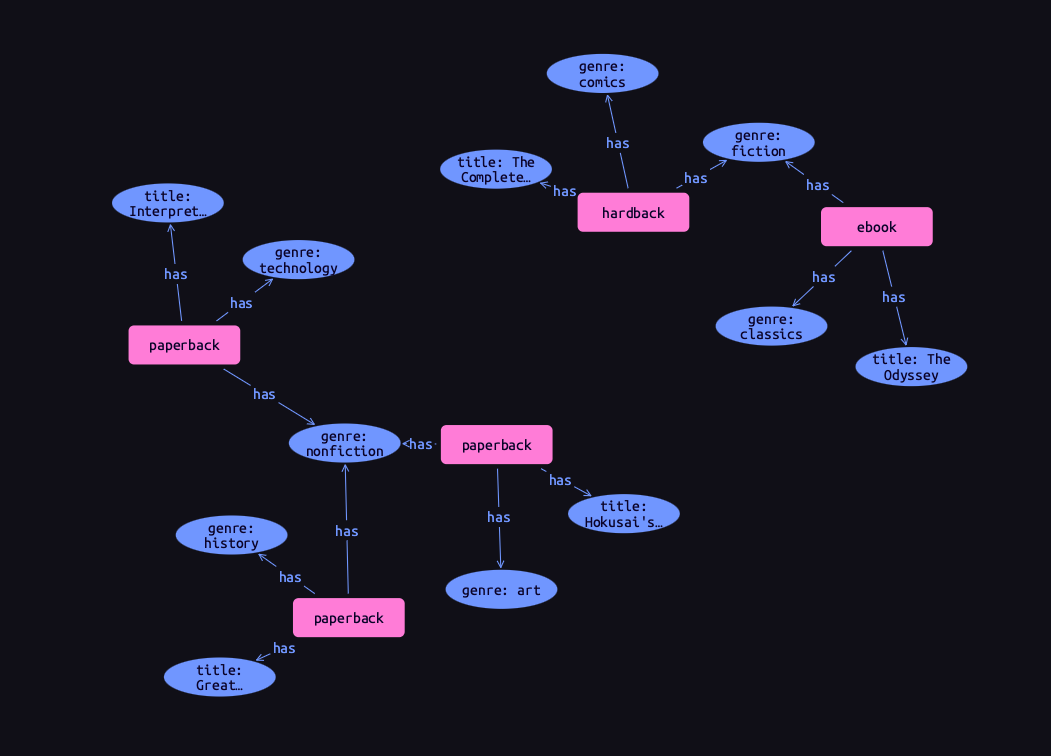
We can see that the vertices representing the fiction and nonfiction genres are shared by multiple books! This is because attributes in TypeDB are globally unique: if we insert multiple attributes with the same type and value, then they will be stored as a single data instance. This means that common attributes can be traversed during pattern matching, leading to significantly more efficient query execution.
|
To retrieve all attributes of an entity or relation, we can query the root type Results
|
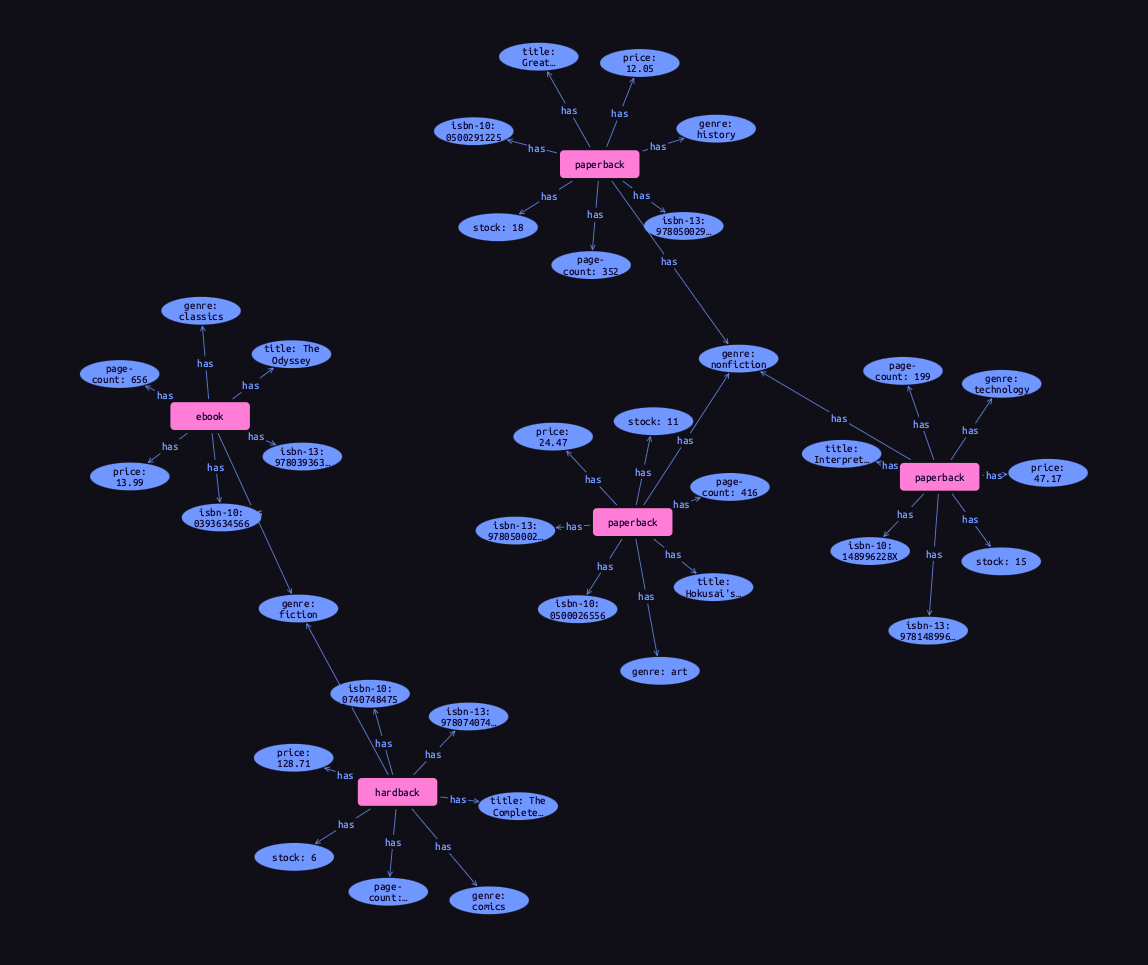
Using relation types
Having explored how to use entity types, we will now look at relation types. In the next Define query, we define a new relation type, which references the existing entity types publisher and book. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
publishing sub relation,
relates publisher,
relates published,
owns year;
publisher plays publishing:publisher;
book plays publishing:published;
year sub attribute, value long;Here we have introduced three new TypeQL keywords:
-
relation: The root type from which all relation types are subtyped. -
relates: Used to define a role for a relation type. Relation types must have at least one role defined. -
plays: Used to define a roleplayer for a relation’s role.
Edges in graph databases are directed, with a start-vertex and an end-vertex indicating direction. In contrast, relations in TypeDB are characterised by named roles rather than direction. For the binary publishing relation type, the endpoints are defined by the publisher and publishing roles. This is highly generalised, and we could define as many roles as we want by using an appropriate number of relates statements. We could, for instance, define a ternary relation type by declaring three roles, or a unary relation type by declaring just one!
For each role defined, we must define the permitted roleplayers with a plays statement. Any number of entity types can be defined to play a given role.
Inserting relations
In the next query, we insert five new publishing relations. Each one references one of the publishers and books we previously inserted. Using a data session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
match
$book-1 isa book, has isbn-13 "9781489962287";
$book-2 isa book, has isbn-13 "9780500026557";
$book-3 isa book, has isbn-13 "9780500291221";
$book-4 isa book, has isbn-13 "9780740748479";
$book-5 isa book, has isbn-13 "9780393634563";
$publisher-1 isa publisher, has name "Springer";
$publisher-2 isa publisher, has name "Thames & Hudson";
$publisher-3 isa publisher, has name "Andrews McMeel Publishing";
$publisher-4 isa publisher, has name "W.W. Norton & Company";
insert
$publishing-1 (published: $book-1, publisher: $publisher-1) isa publishing,has year 1967;
$publishing-2 (published: $book-2, publisher: $publisher-2) isa publishing, has year 2024;
$publishing-3 (published: $book-3, publisher: $publisher-2) isa publishing, has year 2023;
$publishing-4 (published: $book-4, publisher: $publisher-3) isa publishing, has year 2005;
$publishing-5 (published: $book-5, publisher: $publisher-4) isa publishing, has year 2017;This is equivalent to the following Cypher query.
MATCH
(book1:Book { isbn13: "9781489962287" }),
(book2:Book { isbn13: "9780500026557" }),
(book3:Book { isbn13: "9780500291221" }),
(book4:Book { isbn13: "9780740748479" }),
(book5:Book { isbn13: "9780393634563" }),
(publisher1:Publisher { name: "Springer" }),
(publisher2:Publisher { name: "Thames & Hudson" }),
(publisher3:Publisher { name: "Andrews McMeel Publishing" }),
(publisher4:Publisher { name: "W.W. Norton & Company" })
CREATE
(book1)<-[publishing1:PUBLISHING { year: 1967 }]-(publisher1),
(book2)<-[publishing2:PUBLISHING { year: 2024 }]-(publisher2),
(book3)<-[publishing3:PUBLISHING { year: 2023 }]-(publisher2),
(book4)<-[publishing4:PUBLISHING { year: 2005 }]-(publisher3),
(book5)<-[publishing5:PUBLISHING { year: 2017 }]-(publisher4)Unlike the previous Insert queries, this Insert query has two clauses. The match clause matches existing data, but instead of returning the matched data as we did with the Get queries, we reference it in the newly inserted relations. To reference an entity in a relation, we use a relation tuple of the following form immediately after the variable representing the relation.
$relation (role-1: $a, role-2: $b, role-3: $c, ...) isa relation-type;Each element of the tuple consists of the role that the entity will play, followed by the variable representing that entity. As the publishing relation type references two roles (published and publisher), the tuples in the query above have two elements, but the syntax can represent relations with any number of roleplayers as needed.
Reading relations
To query relations, we use the same tuple syntax we use to insert them, as we do in the following query, which retrieves the publishing data we just inserted. Using a data session and read transaction, ![]() run this query.
run this query.
match
$publishing (publisher: $publisher, published: $book) isa publishing;
$publisher isa publisher, has name $name;
$book isa book, has title $title;
get;Results
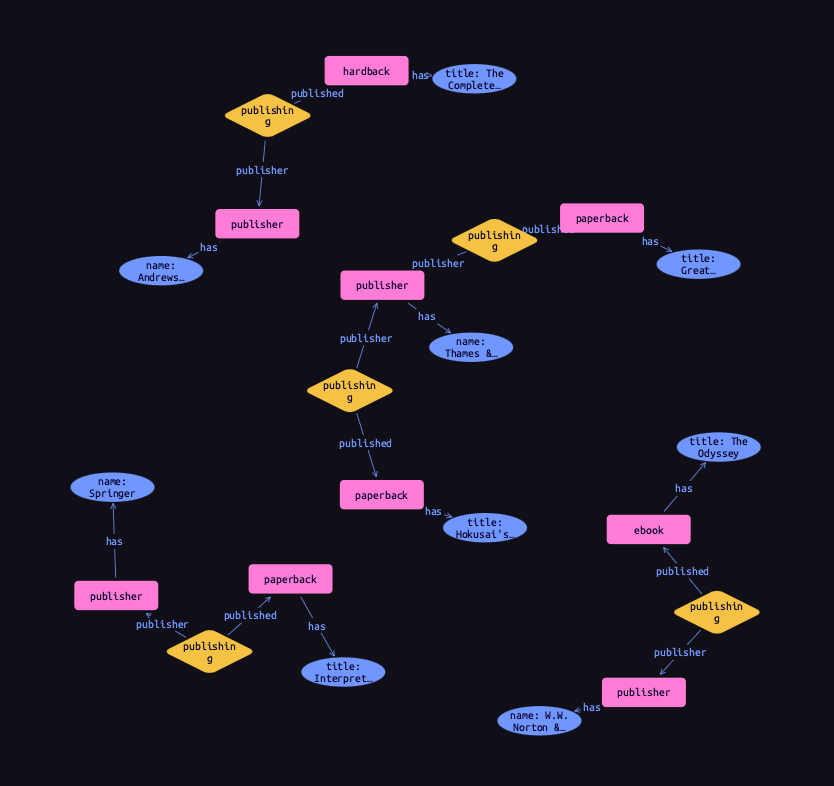
This is equivalent to the following Cypher query.
MATCH
(publisher:Publisher)-[publishing:PUBLISHING]->(book:Book)
RETURN *TypeDB Studio shows relations as yellow diamonds in graphs. Relations are connected to their roleplayers by arrows labeled with the associated role names.
Defining relation type hierarchies
We can define hierarchies of relation types in the same way we define entity type hierarchies. In the next query, we define a contribution relation type and three subtypes: authoring, editing, and illustrating. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
contribution sub relation,
relates contributor,
relates work;
authoring sub contribution,
relates author as contributor;
editing sub contribution,
relates editor as contributor;
illustrating sub contribution,
relates illustrator as contributor;
contributor plays contribution:contributor,
plays authoring:author,
plays editing:editor,
plays illustrating:illustrator;
book plays contribution:work;The roles a relation subtype has depends on how we define them. The query above defines the following relations:
-
contributionwith rolesworkandcontributor -
authoringwith rolesworkandauthor -
editingwith rolesworkandeditor -
illustratingwith rolesworkandillustrator
Here, the work role is inherited by the subtypes of contribution, but the contributor role is overridden for each subtype. To do so, we have introduced a new TypeQL keyword:
-
as: Used in arelatesstatement to override a role of the parent relation type.
We then define the permitted roleplayers for each new role. Because the work role is inherited by the subtypes of contribution, specifying that book plays the role also allows it to play the role in any of the subtypes.
Inserting relations in type hierarchies
As with entities, we only declare the exact type of relations when inserting them into hierarchies, as the schema contains the context necessary to infer supertypes. In the following query we insert several new contributor entities and contribution relations. Using a data session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
match
$book-1 isa book, has isbn-13 "9781489962287";
$book-2 isa book, has isbn-13 "9780500026557";
$book-3 isa book, has isbn-13 "9780500291221";
$book-4 isa book, has isbn-13 "9780740748479";
$book-5 isa book, has isbn-13 "9780393634563";
insert
$contributor-1 isa contributor, has name "Andrews, Kenneth William";
$contributor-2 isa contributor, has name "Dyson, David John";
$contributor-3 isa contributor, has name "Keown, Samuel Robert";
$contributor-4 isa contributor, has name "Wada, Kyoko";
$contributor-5 isa contributor, has name "Katsushika, Hokusai";
$contributor-6 isa contributor, has name "Bynum, William";
$contributor-7 isa contributor, has name "Bynum, Helen";
$contributor-8 isa contributor, has name "Watterson, Bill";
$contributor-9 isa contributor, has name "Homer";
$contributor-10 isa contributor, has name "Wilson, Emily";
(work: $book-1, author: $contributor-1) isa authoring;
(work: $book-1, author: $contributor-2) isa authoring;
(work: $book-1, author: $contributor-3) isa authoring;
(work: $book-2, author: $contributor-4) isa authoring;
(work: $book-2, illustrator: $contributor-5) isa illustrating;
(work: $book-3, editor: $contributor-6) isa editing;
(work: $book-3, editor: $contributor-7) isa editing;
(work: $book-4, author: $contributor-8) isa authoring;
(work: $book-4, illustrator: $contributor-8) isa illustrating;
(work: $book-5, author: $contributor-9) isa authoring;
(work: $book-5, contributor: $contributor-10) isa contribution;This is equivalent to the following Cypher query. As edges cannot typically have multiple labels in graph databases, we are restricted to a single label per edge, and so use the most specific one.
MATCH
(book1:Book { isbn13: "9781489962287" }),
(book2:Book { isbn13: "9780500026557" }),
(book3:Book { isbn13: "9780500291221" }),
(book4:Book { isbn13: "9780740748479" }),
(book5:Book { isbn13: "9780393634563" })
CREATE
(contributor1:Contributor { name: "Andrews, Kenneth William" }),
(contributor2:Contributor { name: "Dyson, David John" }),
(contributor3:Contributor { name: "Keown, Samuel Robert" }),
(contributor4:Contributor { name: "Wada, Kyoko" }),
(contributor5:Contributor { name: "Katsushika, Hokusai" }),
(contributor6:Contributor { name: "Bynum, William" }),
(contributor7:Contributor { name: "Bynum, Helen" }),
(contributor8:Contributor { name: "Watterson, Bill" }),
(contributor9:Contributor { name: "Homer" }),
(contributor10:Contributor { name: "Wilson, Emily" }),
(book1)<-[:AUTHORING]-(contributor1),
(book1)<-[:AUTHORING]-(contributor2),
(book1)<-[:AUTHORING]-(contributor3),
(book2)<-[:AUTHORING]-(contributor4),
(book2)<-[:ILLUSTRATING]-(contributor5),
(book3)<-[:EDITING]-(contributor6),
(book3)<-[:EDITING]-(contributor7),
(book4)<-[:AUTHORING]-(contributor8),
(book4)<-[:ILLUSTRATING]-(contributor8),
(book5)<-[:AUTHORING]-(contributor9),
(book5)<-[:CONTRIBUTION]-(contributor10)Reading relations from type hierarchies
Again as with entities, we can match relations using any of their types. In the following query, we retrieve all the relations we just inserted by matching against the supertype contribution. Using a data session and read transaction, ![]() run this query.
run this query.
match
$contribution (contributor: $contributor, work: $book) isa contribution;
$contributor isa contributor, has name $name;
$book isa book, has title $title;
get;Results
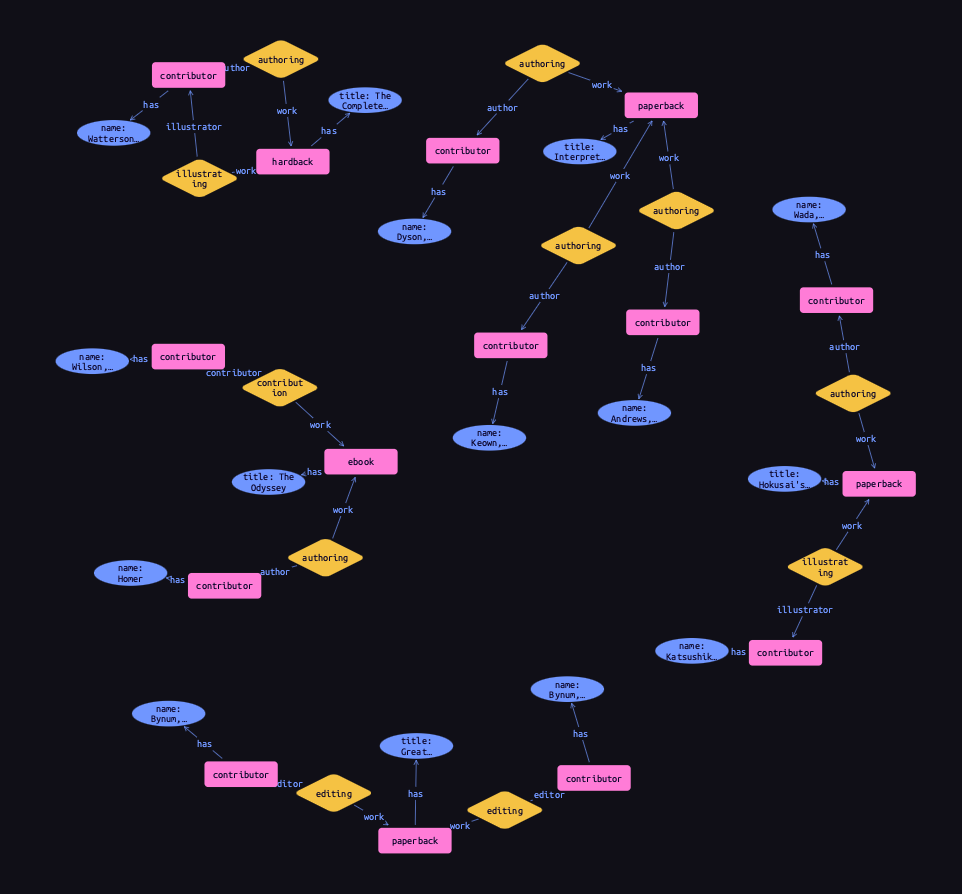
This is equivalent to the following Cypher query.
MATCH
(contributor:Contributor)-[contribution:CONTRIBUTION|AUTHORING|EDITING|ILLUSTRATING]->(book:Book)
RETURN *Because the edges each have a single label, we need to union over the possible labels in order to retrieve all of them with a single pattern. In addition to being more verbose, this approach is also more brittle. If we added new kinds of contribution, they would need to be added to the Cypher query. In contrast, if we define new subtypes of book, the TypeQL query will automatically return them too due to its declarative nature.
Working with nested relations
One of the biggest differences between edges in graph databases and relations in TypeDB is that edges must be between two vertices, whereas relations can be between any number of entities or other relations. Relations that are between other relations are called nested relations. Let’s explore how we can use them, by extending the schema so that we can record the cities in which books were published. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
place sub entity, owns name;
city sub place;
state sub place;
country sub place;
locating sub relation,
relates location,
relates located;
place plays locating:location,
plays locating:located;
publishing plays locating:located;Here we have defined that the existing relation type publishing plays the role located in the new relation type locating. The syntax for defining roleplayers is the same regardless of whether they are entity or relation types. Now we can insert some data. Using a data session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
match
$book-1 isa book, has isbn-13 "9781489962287";
$book-2 isa book, has isbn-13 "9780500026557";
$book-3 isa book, has isbn-13 "9780500291221";
$book-4 isa book, has isbn-13 "9780740748479";
$book-5 isa book, has isbn-13 "9780393634563";
$publishing-1 (published: $book-1) isa publishing;
$publishing-2 (published: $book-2) isa publishing;
$publishing-3 (published: $book-3) isa publishing;
$publishing-4 (published: $book-4) isa publishing;
$publishing-5 (published: $book-5) isa publishing;
insert
$us isa country, has name "United States";
$uk isa country; $uk has name "United Kingdom";
$ny isa state, has name "New York";
$mo isa state, has name "Missouri";
$nyc isa city, has name "New York City";
$kcmo isa city; $kcmo has name "Kansas City";
$ldn isa city; $ldn has name "London";
(location: $us, located: $ny) isa locating;
(location: $us, located: $mo) isa locating;
(location: $ny, located: $nyc) isa locating;
(location: $mo, located: $kcmo) isa locating;
(location: $uk, located: $ldn) isa locating;
(location: $nyc, located: $publishing-1) isa locating;
(location: $ldn, located: $publishing-2) isa locating;
(location: $ldn, located: $publishing-3) isa locating;
(location: $kcmo, located: $publishing-4) isa locating;
(location: $nyc, located: $publishing-5) isa locating;Finally, we query the data to see the resulting graph. Using a data session and read transaction, ![]() run this query.
run this query.
match
$book isa book, has title $title;
$publisher isa publisher, has name $publisher-name;
$publishing ($publisher, $book) isa publishing;
$city isa city, has name $city-name;
$locating ($city, $publishing) isa locating;
get;Results
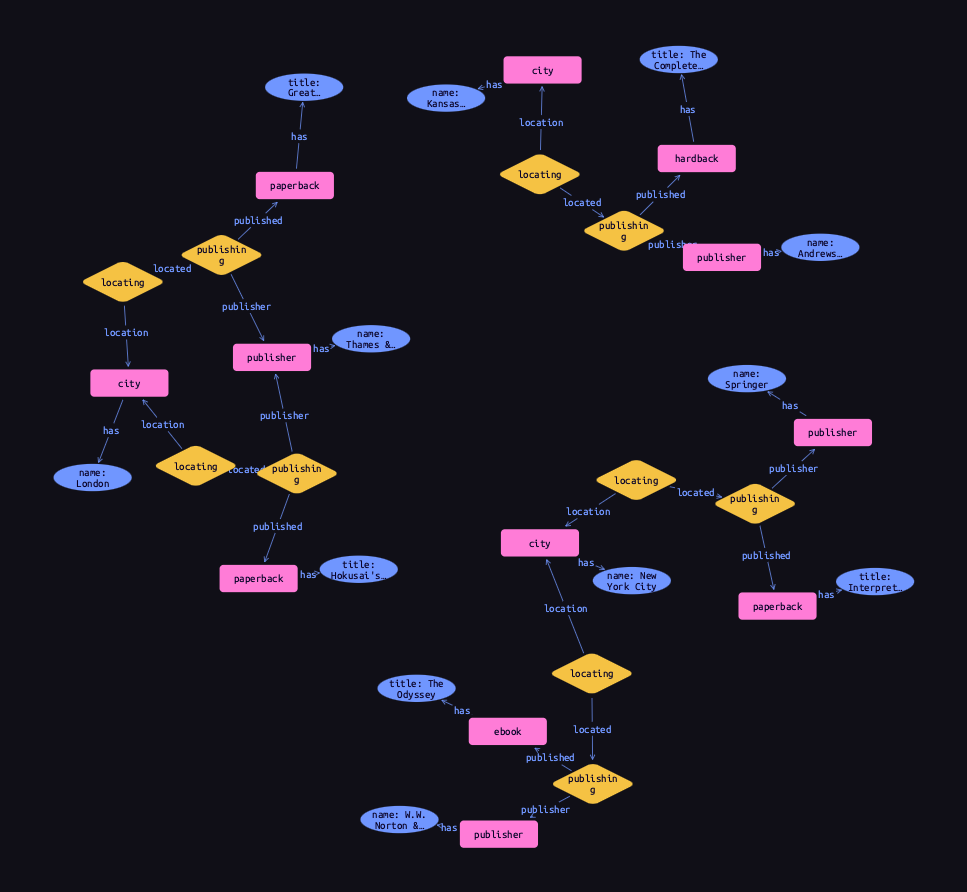
|
If a relation’s roles are unambiguous given the context of the query, then they can be omitted altogether. The above query is equivalent to: |
Nested relations are a powerful way to model data, not normally possible with graph databases. Another option in this case would have been to make publishing a ternary relation type relating publisher, published, and location, but this pattern is more general, as we can use the locating relation to record the locations of other things, as we do for the cities and states we just inserted.
Working with rule inference
TypeDB allows us to infer new data based on existing data by using rules. Rules form part of the schema and are added to the database with a Define query. Let’s explore how this can be applied. The following query is intended retrieve books that were published in the United States. Using a data session and read transaction, ![]() run this query.
run this query.
match
$book isa book, has title $title;
$publisher isa publisher, has name $publisher-name;
$publishing ($publisher, $book) isa publishing;
$us isa country, has name "United States";
$locating ($us, $publishing) isa locating;
get;However, we get no results. This is because we haven’t actually inserted locating relations between the publishing relations and the countries of publication, only the cities. We could insert additional relations, but this would lead to redundancy. It is better to do this with a rule, as we define in the following query. Using a schema session and write transaction, ![]() run this query, then
run this query, then ![]() commit the transaction.
commit the transaction.
define
rule transitive-locations:
when {
(location: $parent-place, located: $child-place) isa locating;
(location: $child-place, located: $x) isa locating;
} then {
(location: $parent-place, located: $x) isa locating;
};This rule makes locating relations transitive by creating new relations that bridge every two existing ones. A rule consists of a condition and a conclusion, located in the when and then blocks respectively. Wherever in the data the condition is met, the conclusion is applied. Functionally, the above rule is very similar to the following Insert query, which should not be run.
match
(location: $parent-place, located: $child-place) isa locating;
(location: $child-place, located: $x) isa locating;
insert
(location: $parent-place, located: $x) isa locating;Unlike Insert queries, which are run once and insert the data on disk, rules are run at query-time and generate the data in memory. This means that the generated relations will use the most up-to-date data available.
This particular rule also has two powerful properties:
-
It can apply recursively, creating a new relation to bridge a chain of existing ones of any length.
-
It doesn’t specify the type of the variable
$x, so will create new relations describing the transitive locations of anything that has a location recorded.
Reading inferred data
Inferred data is read in the same way as data on disk, but rule inference must first be enabled. To do so in TypeDB Studio, use the inference toggle (![]() ) in the top toolbar. If we re-run the above query with inference enabled, we should now get results!
) in the top toolbar. If we re-run the above query with inference enabled, we should now get results!
Results
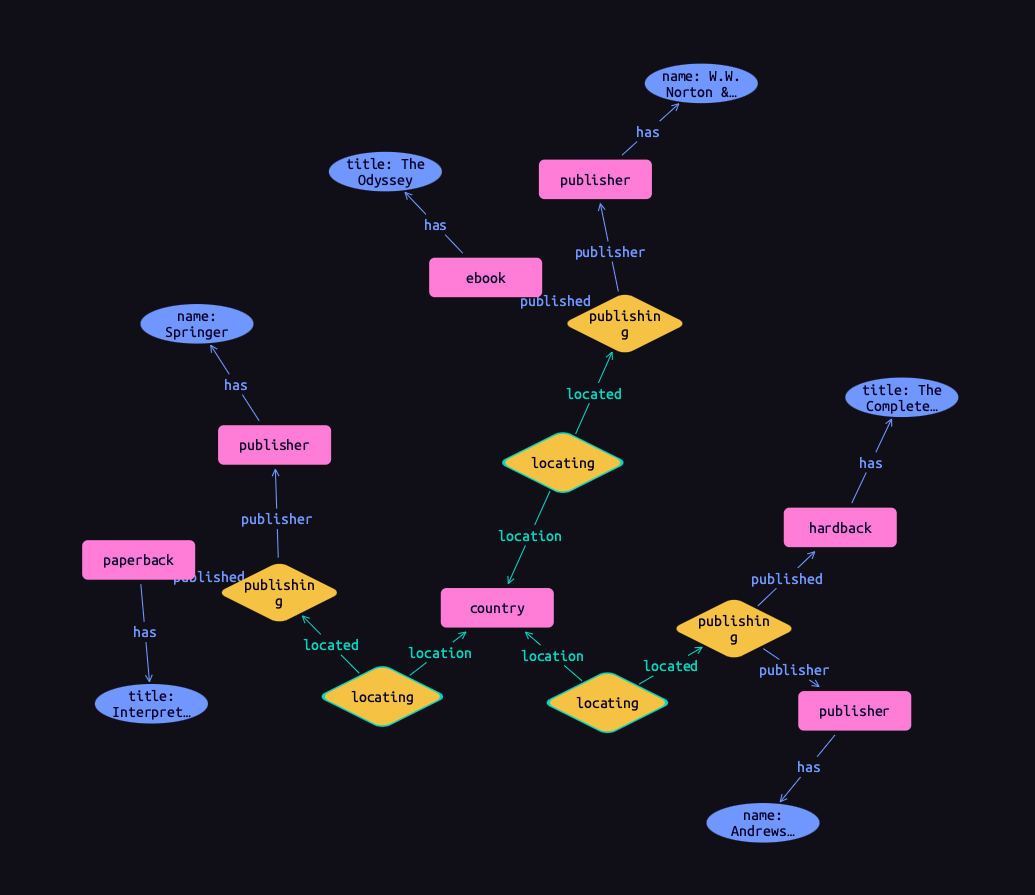
Data generated by rule inference is shown with a green outline in TypeDB Studio’s graph visualizations.
Retrieving the entire database as a graph
During prototyping, it is often useful to view the entire database as a graph. To do so, we can use the following parametric query. Using a data session and read transaction, ![]() run this query. If inference is enabled, the graph will include all inferred relations.
run this query. If inference is enabled, the graph will include all inferred relations.
match
$x isa $t;
get $x;Results
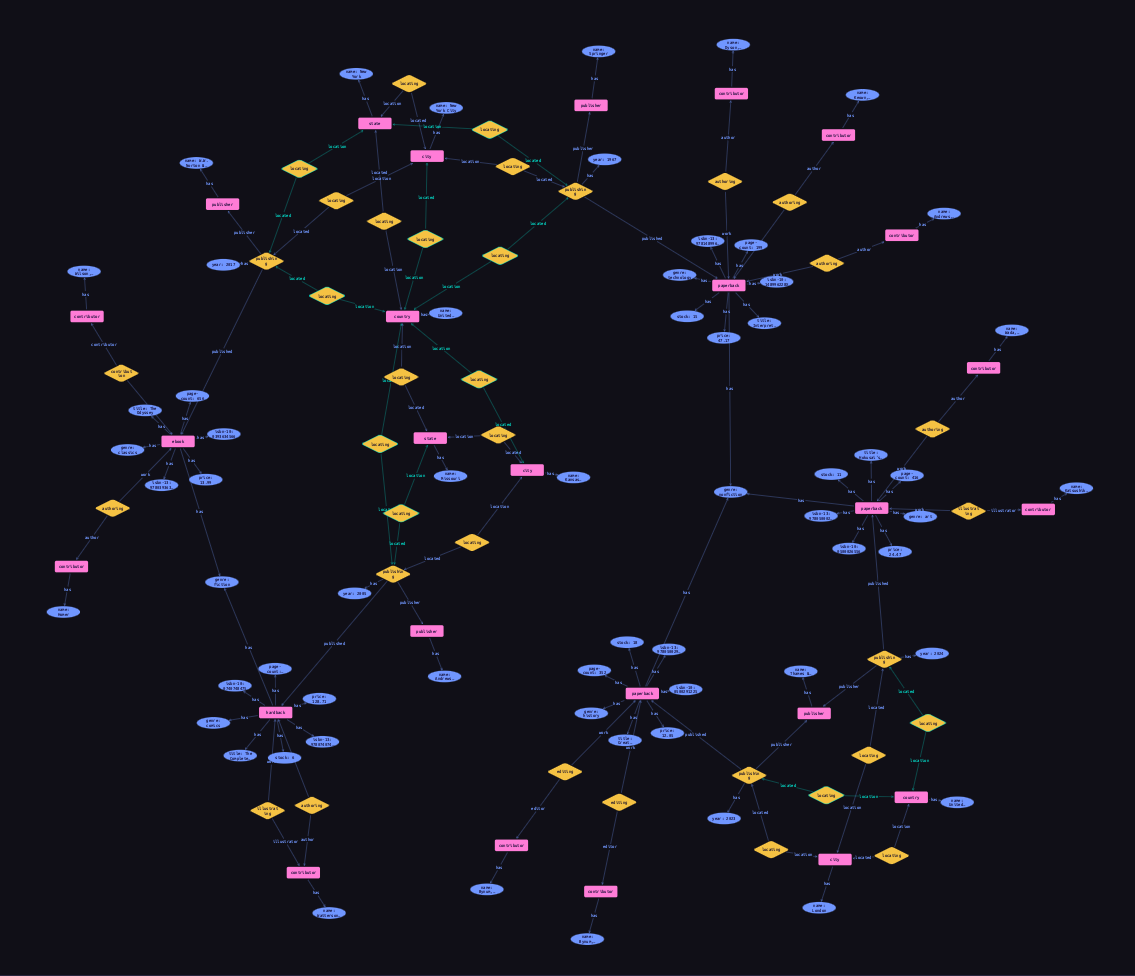
This will retrieve every entity, relation, and attribute in the database. Note that graph visualizations can be performance intensive for very large result sets. Use this query with caution!
Retrieving data in JSON format
In addition to viewing results as a graph visualization, we can also retrieve the results in JSON format using a Fetch query. Fetch queries can only retrieve attributes, not entities or relations as they have no text representation. Let’s examine this Get query from earlier.
match
$book isa book, has title $title;
$publisher isa publisher, has name $publisher-name;
$publishing ($publisher, $book) isa publishing;
$city isa city, has name $city-name;
$locating ($city, $publishing) isa locating;
get;It has three variables representing attributes: $title, $publisher-name, and $city-name. We can turn it into a Get query by replacing the get clause with a fetch clause containing these three variables. Using a data session and read transaction, ![]() run this query.
run this query.
match
$book isa book, has title $title;
$publisher isa publisher, has name $publisher-name;
$publishing ($publisher, $book) isa publishing;
$city isa city, has name $city-name;
$locating ($city, $publishing) isa locating;
fetch
$title;
$publisher-name;
$city-name;Results
{
"city-name": { "value": "New York City", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"publisher-name": { "value": "W.W. Norton & Company", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"title": { "value": "The Odyssey", "type": { "label": "title", "root": "attribute", "value_type": "string" } }
}
{
"city-name": { "value": "New York City", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"publisher-name": { "value": "Springer", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"title": { "value": "Interpretation of Electron Diffraction Patterns", "type": { "label": "title", "root": "attribute", "value_type": "string" } }
}
{
"city-name": { "value": "Kansas City", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"publisher-name": { "value": "Andrews McMeel Publishing", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"title": { "value": "The Complete Calvin and Hobbes", "type": { "label": "title", "root": "attribute", "value_type": "string" } }
}
{
"city-name": { "value": "London", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"publisher-name": { "value": "Thames & Hudson", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"title": { "value": "Great Discoveries in Medicine", "type": { "label": "title", "root": "attribute", "value_type": "string" } }
}
{
"city-name": { "value": "London", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"publisher-name": { "value": "Thames & Hudson", "type": { "label": "name", "root": "attribute", "value_type": "string" } },
"title": { "value": "Hokusai's Fuji", "type": { "label": "title", "root": "attribute", "value_type": "string" } }
}